|
"The Official Guide to Programming with OmniMark" |
|
| 1.0 | The OmniMark® Programming Model |
| 2.0 | OmniMark® Quick Reference |
| 3.0 | Declarations |
| 4.0 | Rules |
| 5.0 | Actions |
| 6.0 | Elements, Attributes, and Data-Attributes |
| 7.0 | Conditions |
| 8.0 | Patterns |
| 9.0 | String Expressions |
| 10.0 | Numeric Expressions |
| 11.0 | Miscellaneous Components |
| 12.0 | Functions |
| 13.0 | Macros |
OmniMark has been designed to be as easy to learn and use as possible. This is accomplished in part by providing you with a model of document processing which is intuitive but not limiting.
Many programming problems, such as event, hierarchy, and memory management, are handled automatically by OmniMark, freeing you to concentrate on the task you are trying to accomplish. At the same time, OmniMark does not do so many things for you automatically that it begins to get in the way. OmniMark works with you by providing a simple, straight-forward operating model and a powerful problem solving programming environment.
OmniMark is a data driven language. That is, events that occur in the data being read by OmniMark cause a rule to be selected. Two fundamental types of data events are recognized by OmniMark: events in SGML documents and patterns in non-SGML documents. Common examples of events in SGML documents include the start of an element or an entity reference. In other documents, an event is finding a unique pattern of bits and characters in the document.
Declarations and rules make up OmniMark programs. Declarations affect overall processing. Rules are triggered by various events, and contain actions that specify which calculations and operations to carry out. Both individual actions and rules may have conditions attached to them. Such a rule or action is carried out only if its condition is true.
With Version 3, OmniMark now provides a traditional 3GL (third generation language) mode, as well as a 4GL.
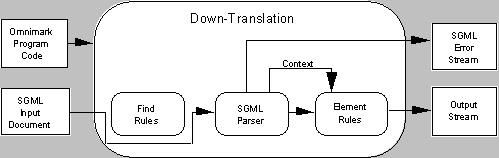
As a 4GL, OmniMark performs four different types of document conversions: down-translation, up-translation, context-translation, and cross-translation. These are called aided translation types .
In the following illustrations, shaded line boxes indicate the OmniMark functions not participating in that particular type of translation.
A down-translation is a translation whose input is an SGML document. The output of a down-translation could be the input of a text formatter or the input to a database. The output could also be another SGML document either a cleaned up version of the input, or some restructuring of it.
An up-translation is a translation whose output is a complete SGML document or a document instance. If the output does not contain a DTD, OmniMark must be told where to find it. In either case, the generated document instance is parsed with respect to the specified DTD and any errors are reported. OmniMark places no restrictions on the format of the input to an up-translation; most often the input is a data file compatible with a non-SGML text processing system.
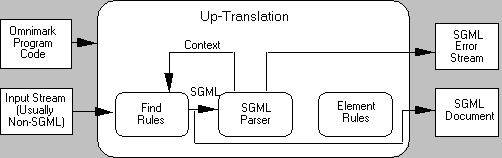
A context-translation is a translation that converts text from a non-SGML representation of a structured document to another form (often SGML), using SGML as an intermediate form. Patterns in the original document suggest its structure and allow conversion to SGML. OmniMark parses the SGML form and, using the parser, corrects structure errors. The final output makes use of the structure discovered by the parser to produce a fully marked-up document, a minimized document, or some non-SGML form.
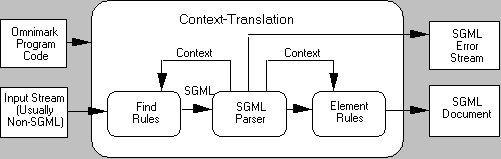
A cross-translation is a translation that converts a document from one arbitrary form to another. Cross-translations do not make any use of the parser.
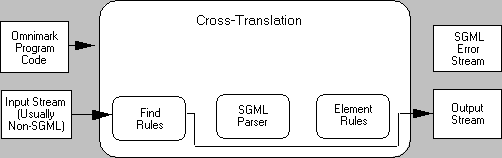
When no translation type is specified, OmniMark runs as a program . PROCESS rules explicitly process files from the command-line (for example). SUBMIT actions are used to emulate cross-translations. SGML-PARSE actions are used to emulate the other three aided translation types.
This guide provides a concise overview of the OmniMark Programming Language. Its purpose is to show the organization of the language. Consult the OmniMark Programmer's Guide for further details on how to write OmniMark programs.
Much of this guide consists of lists showing OmniMark syntax and then a description of that syntax. When looking at the syntax of a statement, remember that:
Keywords appear in capital letters in this guide.
Italicized terms are either parameters or refer to OmniMark constructs. If the italicized term is not described where it is used, check the table at the end of this section. This table describes the term or indicates where it is described.
Where a single term or keyword is optional, it appears underlined.
Grouping is denoted in two different forms. In the first form, one or more terms appear between braces ("{" and "}"), and support the following repetition factors:
A question mark ("?") after the braces indicates that the terms are optional.
An asterisk ("*") indicates that they are optional and may be repeated.
A plus sign ("+") indicates that they are required and may be repeated.
Options within a group are separated by vertical bars ("|"). If the specific order of two or more options doesn't matter, they are separated with an ampersand ("&"). Parentheses ("(" and ")") denote themselves.
OmniMark comments start with a semi-colon (";") anywhere on a line, except inside strings, and continue to the end of the line.
| Term | Description |
| action | See Actions. |
| aided translation types | See Translation Types. |
| alias | A name that stands in place of the real name of an element or attribute. Used in iterations as a convenient way of referring to the current item. |
| ancestry-qualifier | See Ancestry Qualifiers. |
| attribute | Name of an attribute as it appears in the document type definition (DTD). |
| attribute-identifier | See Attribute Identifiers. |
| character | A single character (or text representing a specific character) within quotation marks. For example, "a", "#", and "%n" are characters. |
| comparer | See Comparisons. |
| condition | See Conditions. |
| counter | Name of a counter. See Shelf Declarations. |
| data-attribute | Name of a data-attribute as it appears in the DTD. |
| data-attribute-identifier | See Attribute Identifiers. |
| entity | Name of an entity as it appears in the DTD. |
| gi | The generic identifier (name) of an element as it appears in the DTD. |
| group | Name of a group as defined in the GROUP declaration (see Other Declarations). |
| index/item | See Shelf Indexes. |
| insertion | See Insertion Points. |
| item | See Shelf Indexes. |
| local | See Local Declarations. |
| name | Text (without quotation marks) specifying a name. |
| number | An integer between -2,147,483,647 and 2,147,483,647. |
| numeric-expression | See Numeric Expressions. |
| pattern | See Patterns. |
| pattern-primary | See Primary Patterns. |
| program | 3GL-like OmniMark programs without an explicit translation-type. |
| shelf-declaration | See Shelf Declarations. |
| shelf-name | Name of a shelf. See Shelf Declarations. |
| shelf-type | See Shelf Declarations. |
| static-string | See Static Strings. |
| stream | Name of a stream. See Special Streams. |
| string-expression | Any of the types of strings defined in String Expressions. |
| switch | Name of a switch. See Shelf Declarations. |
| translation-type | See Aided Translation Types. |
The term "scope" is now used to describe parts of OmniMark V3. A scope is a sequence of zero or more actions that may be headed by a sequence of declarations. The declarations are in effect only for the duration of the sequence of actions. Some OmniMark scopes include the actions of a rule, the actions between a "DO" and an "ELSE" or "DONE", between a "REPEAT" and the matching "AGAIN". Scopes can nest.
Convert non-SGML documents from one format to another
(including SGML) using an intermediate SGML representation.
Convert documents from one format to another without using SGML parsing.
Convert SGML documents to some other format (including SGML). This is the default.
Convert non-SGML documents into SGML.
Default byte-to-number conversions carried out with the
ordering specified by number.
Default number-to-byte conversions carried out with the
ordering specified by number.
Use character
instead of % as the format item escape character.
Extends the set of characters to be considered alphabetic. Default
is the 26 English lower-case letters and their upper-case equivalents.
(LETTERS in V2).
Specifies the default location of external functions.
Run programs written for versions previous to V3. There is no
unaided translation type; programs default to
down-translations. Shelf types must always be specified.
Referent-status
is one of REFERENTS-ALLOWED,
REFERENTS-DISPLAYED, or REFERENTS-NOT-ALLOWED.
Text-mode-status
is one of BINARY-MODE or TEXT-MODE.
Used to specify how OmniMark should map characters in names
to upper-case.
See Functions.
Tells OmniMark compiler to ignore upper/lower-case distinctions for external entity names (YES) or to not ignore these distinctions (NO). NO is the default.
Tells OmniMark compiler to ignore upper/lower-case distinctions for all other SGML names (YES) or to not ignore these distinctions (NO). YES is the default.
Use static-string
as the newline sequence (%n) instead of
the system's newline sequence, and open files as binary files rather
than text files. This declaration is deprecated in OmniMark V3, in
favor of using the TEXT-MODE and BINARY-MODE stream modifiers where
needed.
Preferred width of OUTPUT stream given by first value,
maximum allowed value, if desired, given by the second.
The actual line-breaking is controlled by the REPLACEMENT-BREAK
and INSERTION-BREAK rules.
Multi-token attribute values delimited by static-string
when printed with the %v format item.
Defines types and sizes of shelves (arrays) used
throughout the program (shelf-declaration
is defined
in Shelf Declarations).
Precedes all rules belonging to the named group.
Takes effect until another GROUP declaration is given.
Temporarily suspend processing this file and compile
the OmniMark declarations and rules given in the file static-string
.
Lines written to the OUTPUT stream can be broken with
static-string
in order to meet the width restrictions
given in the BREAK-WIDTH declaration.
Unlike most other declarations, INSERTION-BREAK can be qualified by a condition
, to indicate where in the processing the declaration applies.
The second string
gives the system-specific name
of the file associated with the public identifier
given in the first string-expression
.
Defines macros used by the OmniMark compiler
(see Macros).
Lines written to the OUTPUT stream can be broken by replacing
character
with static-string
in order to meet
the width restrictions given in the BREAK-WIDTH declaration.
Unlike most other declarations, REPLACEMENT-BREAK can be qualified by a condition
, to indicate where in the processing the declaration applies.
Gives the symbolic strings to associate with numeric values
as accessed by the %y format item.
All OmniMark rules consist of a header, that determines when the rule is selected for processing, an optional set of local declarations, and an optional sequence of actions to be performed when the rule is selected. The output streams available to a rule depend on which "domain" it belongs to: Element Domain, Find Domain and SGML Error Domain.
The rules in this section belong to the Element Domain unless otherwise indicated. Element Domain rules are allowed in context-translations and down-translations. In addition, the SGML-ERROR rule and EXTERNAL-TEXT-ENTITY rule are allowed in up-translations.
DATA-CONTENT condition
local*
action+
Used to process strings of data characters within an SGML document.
Only one DATA-CONTENT rule may have a successful condition
(or no condition) for any segment of PCDATA.
DOCUMENT-END condition
local*
action*
Performs the specified actions after the end of the SGML document.
DOCUMENT-END rules are performed in the order they appear
in the OmniMark program.
In context-translations,
DOCUMENT-END rules are performed after the FIND-END rules.
DOCUMENT-START condition
local*
action*
Performs the specified actions before the start of the SGML document.
DOCUMENT-START rules are performed in the order
they appear in the OmniMark program.
In context-translations,
DOCUMENT-START rules are performed before the FIND-START rules.
DTD-END condition
local*
action*
Performs the specified actions immediately following the end of the DTD.
DTD-END rules are performed in the order they appear
in the OmniMark program.
DTD-START condition
local*
action*
Performs the specified actions as soon as the SGML parser has determined the name of the document element. Usually occurs one character after the end of the element name, as in:
<!DOCTYPE HTMLPLUS -- DTD-START fires at the space after the "S" -- [
ELEMENT {gi | #IMPLIED} condition
local*
action*
Performs the specified actions when the specified
generic identifier occurs in the SGML document.
Only one ELEMENT rule may have a successful condition
(or no condition) for any element's start-tag.
The #IMPLIED form of these rules is selected when
no rule that explicitly lists generic identifiers or entity names
can be selected and any condition
is met.
EPILOG-START condition
local*
action*
Performs the specified actions immediately following the end tag of the document element in the document instance, or, if the document element's end tag is omitted, at the end of the document prior to performing any DOCUMENT-END rule.
EPILOG-START rules are performed in the order they appear
in the OmniMark program.
EXTERNAL-DATA-ENTITY {entity | #IMPLIED} condition
local*
action*
Performs the specified actions
when
the specified external entity
occurs in the SGML document.
Only one EXTERNAL-DATA-ENTITY rule may have a
successful condition (or no condition)
for any reference to an external data entity.
(EXTERNAL-ENTITY is a synonym for EXTERNAL-DATA-ENTITY.)
EXTERNAL-TEXT-ENTITY
{#CAPACITY | #CHARSET | #DOCUMENT | #DTD | #SYNTAX | #IMPLIED | entity}
condition
local*
action*
Performs the specified actions when an SGML entity occurs that matches the
specified type or name.
Output in the EXTERNAL-TEXT-ENTITY is done as part of the Find domain because its output is input to the SGML parser.
INVALID-DATA condition
local*
action*
Performs the specified actions when the SGML parser detects text
that it cannot coerce into a valid form.
MARKED-SECTION marked-section-type condition
local*
action*
Performs the specified actions when a marked section of the specified
type is encountered.
Valid values for marked-section-type
are CDATA, IGNORE, INCLUDE-END,
INCLUDE-START, and RCDATA.
PROCESSING-INSTRUCTION pattern condition
local*
action*
Performs the specified actions when a processing instruction
encountered in the SGML document matches the given pattern.
The first rule found in the OmniMark program is used;
other ones that might also match are ignored.
PROLOG-END condition
local*
action*
Performs the specified actions immediately prior to the start tag of the document element in the document instance, or, if the document element's start tag is omitted, immediately prior to the start tag, text, marked section declaration or USEMAP declaration that starts the instance.
PROLOG-END rules are performed in the order they appear
in the OmniMark program.
PROLOG-IN-ERROR condition
local*
action*
This rule fires at the end of an SGML Document prolog (SGML
Declaration, if given, and DTD) that contains errors. More than one
can fire. OmniMark halts by default after the last one fires.
SGML-COMMENT condition
local*
action*
Performs the specified actions when an SGML comment occurs in the document
instance.
SGML-DECLARATION-END condition
local*
action*
Performs the specified actions after the end of the SGML Declaration.
SGML-DECLARATION-END rules are performed in the order they appear
in the OmniMark program.
SGML-ERROR condition LOG
local*
action*
Performs the specified actions whenever an error detected by the
SGML parser satisfies the condition, if given.
If the LOG keyword appears, the error message as provided to OmniMark
is written to the log stream.
In addition, the condition and actions can access parts of this
message by examining several pre-defined pattern variables.
TRANSLATE pattern condition
local*
action*
Performs the specified actions whenever text from the SGML document
matches the given pattern.
The first rule found in the OmniMark program is used;
other ones that might also match are ignored.
Input Processing rules are used in context-translations and up-translations to preprocess data prior to it being fed to the SGML parser. Input Processing rules are also used in cross-translations, in which case they do all the processing of the input data.
FIND pattern condition
local*
action*
Performs the specified actions whenever text from the input
matches the given pattern.
The first rule is used; other ones that might also match are ignored.
FIND-END condition
local*
action*
Performs the specified actions after the end of the
input document has been processed.
FIND-END rules are performed in the order they appear in the OmniMark program.
In context-translations,
FIND-END rules are performed before the DOCUMENT-END rules.
FIND-START condition
local*
action*
Performs the specified actions before the start of the input document.
FIND-START rules are performed in the order they appear in the OmniMark program.
In context-translations,
FIND-START rules are performed after the DOCUMENT-START rules.
Programs that do not start with an aided translation type or "DECLARE HERALDED NAMES" are process program s. Input file processing and SGML processing must be started explicitly with the following rules:
PROCESS-END condition
local*
action*
Performs the specified actions after all other rules have fired.
PROCESS-END rules are performed in the order they appear in the OmniMark program.
PROCESS-END rules are allowed in all aided translation types
as well
as programs
.
PROCESS-START condition
local*
action*
Performs the specified actions before any other rules fire.
PROCESS rules are performed in the order they appear in the OmniMark program.
PROCESS-START rules are allowed in all aided translation types
as well
as programs
.
PROCESS condition
local*
action*
Performs the specified actions after all PROCESS-START rules have
been performed.
PROCESS rules are performed in the order they appear in the OmniMark program.
PROCESS rules are not allowed when an aided
translation type
is specified.
Any action may be guarded by placing a condition after it. Although the action appears before the condition, the condition is tested first. The action is then carried out only if the condition is true.
Turns the indicated switch on.
Removes all items from a shelf.
Closes the indicated stream.
Copies the entire contents of a shelf to another shelf.
Moves the entire contents of a shelf to another shelf,
effectively clearing the first shelf.
Turns the indicated switch off.
Decreases the value of the indicated counter by the value of
numeric-expression
,
or by one (1) if no numeric expression is included.
Closes and removes the contents of the indicated stream.
Terminates the currently nested level of a REPEAT or a REPEAT SCAN.
Returns FALSE from SWITCH functions.
Stops processing under program control.
Stops processing under program control. Referents are not expanded.
Increases the value of the indicated counter
by the value of numeric-expression
,
or by one (1) if no numeric expression is specified.
Adds a new value to the shelf,
initializing the new value according to its type:
counters are set to one, switches are deactivated, and streams
unopened.
If no insertion
is specified, the item is added to the right
side of the shelf.
When group
is specified, that group of rules becomes active;
any rules in the #IMPLIED group are still active.
When #IMPLIED is specified, all groups of rules except
the #IMPLIED group become inactive.
If a function call is given, it must be an EXTERNAL OUTPUT function.
Writes text to the active stream or streams.
Redefines the active streams in the FIND domain.
The streams listed in the OUTPUT-TO action becomes the only active streams.
Puts the value of string-expression
into stream
.
Removes one item from the indicated shelf.
Removes the key of the indicated shelf.
Allows additional text to be written to the end of a buffer,
referent, file, or EXTERNAL OUTPUT function,
that has been opened and closed.
Sets the value of the indicated counter to numeric-expression
,
or to one (1) if no numeric expression is included.
Return from the current function, with the specified value if it's a
value-returning function.
See The SET Action.
Specifies how newline sequences written to the SGML stream are to be
converted into record-end and record-start characters as used by the SGML parser.
Specifies how record-end characters emitted by the SGML parser are to be
transformed for the element rules.
Specifies how record-end characters emitted by the SGML parser are to be
transformed for the element rules.
Suspends processing of the current input file while applying the FIND rules
to the text of string-expression
.
If FILE is specified,
string-expression
is treated as a file name and that file's text
is submitted to the FIND rules.
Returns TRUE from SWITCH functions.
Discard the content of an ELEMENT, DATA-CONTENT, MARKED-SECTION or
SGML-COMMENT.
Runs internal system-integrity tests.
The SET action is OmniMark's general assignment statement. It has the following forms:
Initializes the contents of a buffer and associates the buffer
with the indicated stream.
Initializes the counter to the specified value.
Initializes the target indicated by the call to an EXTERNAL OUTPUT function.
Specifies the external name that function-name
is defined as.
Opens an unnamed stream, attaches the stream to a file
named string-expression1
,
writes the text in string-expression2
to the stream,
and then closes the stream.
Specifies the library where function-name
can be found.
Sets the key of the indicated shelf item to the specified value.
Creates a new item on the shelf, with an optional key, and
initializes its value. Modifiers are allowed only for 'SET NEW
STREAM' ('SET NEW BUFFER' is a synonym).
Sets the key of the indicated shelf item to the specified value.
If no insertion
is specified, the item is added to the right
side of the shelf.
Opens an unnamed stream, attaches the stream to a referent
named string-expression1
,
writes the text in string-expression2
to the stream,
and then closes the stream.
Initializes the switch to the specified value.
Initializes the current referent's value in a 'REPEAT OVER
REFERENTS' action.
This action starts processing another document through the SGML parser, suspends current activity at the point of the "%c". Its form is:
DO SGML-PARSE document-type SCAN source-type
local*
action+ ; includes a "%c"
DONE
document-type is one of:
DOCUMENT {CREATING DTDS KEY string-expression}?
A complete SGML document, with its own SGML Declaration.
INSTANCE {WITH DOCUMENT-ELEMENT string-expression}?
WITH {CURRENT DTD | DTDS KEY string-expression}
An instance, or part of an instance with outer element given by the
named DOCUMENT-ELEMENT.
SUBDOCUMENT {CREATING DTDS KEY string-expression}?
An SGML document that uses the current SGML Declaration.
and source-type is one of:
INPUT input function call
input function call
is an internal void function. Its OUTPUT
actions write to the SGML parser.
string-expression
Feeds string-expression
to the SGML parser.
Control structures provide ways of grouping several actions together.
DO WHEN condition
local*
action*
{ELSE WHEN condition
local*
action*}*
{ELSE
local*
action*}?
DONE
In the DO WHEN-ELSE control structure, actions are performed
when the condition is met.
This control structure is analogous to the IF-THEN-ELSE construct
used in some programming languages.
DO SELECT numeric-expression
{CASE constant numeric-expression
local*
action*}*
{ELSE
local*
action*}?
DONE
Similar to DO-WHEN-ELSE: executes faster, but all the CASE values
must be constant.
DO local* action* DONE
This second, simpler form of the DO control structure,
just groups several actions together.
Its most common use is to let a using-prefix apply to more than one action.
REPEAT local* action+ AGAIN
The actions are repeated in order until an EXIT action is met.
One of the actions must be or contain an EXIT action.
The actions within a REPEAT OVER structure are repeated once for each item on the shelf. The #FIRST, #LAST, and #ITEM pre-defined values can be used inside REPEAT OVER actions.
REPEAT OVER shelf-type shelf-name local* action* AGAIN
Iterate through shelves of counters, switches or streams.
REPEAT OVER REFERENTS local* action* AGAIN
Iterate through the defined and used referents.
REPEAT OVER ATTRIBUTE attribute ancestry-qualifier local* action* AGAIN
Iterates through the tokens of a list-valued element attribute (NAMES, NUMBERS, NMTOKENS, NUTOKENS, ENTITIES or IDREFS).
REPEAT OVER DATA-ATTRIBUTE data-attribute {OF (attribute-identifier)}
local*
action*
AGAIN
Iterates through the tokens of a list-valued data-attribute (NAMES, NUMBERS, NMTOKENS or NUTOKENS).
REPEAT OVER SPECIFIED ATTRIBUTES ancestry-qualifier AS alias local* action* AGAIN
Iterates through the attributes associated with an element.
If SPECIFIED appears, the shelf of attributes only contains those
specified in the element's start tag.
REPEAT OVER SPECIFIED
DATA-ATTRIBUTES {OF (attribute-identifier)}? AS alias
local*
action*
AGAIN
Iterates through the data-attributes associated with an attribute.
If SPECIFIED appears, the shelf of data-attributes only contains those
specified in the entity's declaration.
REPEAT OVER REVERSED CURRENT ELEMENTS AS alias local* action* AGAIN
Iterates through all currently open elements.
When REVERSED is specified,
the iteration starts from the last (innermost) opened element.
Otherwise, it begins from the first (outermost) opened one.
The following control structures can be used for analyzing text:
DO SCAN FILE string-expression
{MATCH UNANCHORED pattern condition
local*
action*}+
{ELSE
local*
action*}?
DONE
The DO SCAN construct examines a stream (string) or file using the
given patterns and conditions.
Each condition and pattern is tested.
For the first condition, if any, and pattern that succeeds,
the following set of actions is performed.
If no conditions and patterns
succeed, the set of actions following ELSE (if any) are performed.
If UNANCHORED is not specified following MATCH,
a pattern must match at the start of the stream or file.
If UNANCHORED is specified, a pattern can match anywhere
within the stream or file.
REPEAT SCAN FILE string-expression
{MATCH UNANCHORED pattern condition
local*
action*}+
AGAIN
The REPEAT SCAN construct examines a stream or file
in the same manner as DO SCAN,
except that if a set of actions that follow them are performed,
the REPEAT SCAN is repeated starting immediately
following the last thing that was matched.
REPEAT SCAN terminates when no pattern or conditions succeed.
These control structures are used to quickly skip over the input while matching it. They can appear in FIND-START and FIND rules.
DO SKIP PAST numeric-expression {OVER string-expression}?
local*
action*
{ELSE
local*
action*}?
DONE
The number of characters indicated in numeric-expression
are skipped over; if there are not that many characters
left in the input to process,
an error message is printed and the system halts.
If the OVER string-expression
is included, the number of characters indicated in numeric-expression
are skipped over before searching for string-expression.
DO SKIP OVER string-expression
local*
action*
{ELSE
local*
action*}?
DONE
Characters are skipped over until string-expression
is found.
If no string expression is found, the actions under the ELSE are performed,
and no characters will remain in the input.
A USING prefix selects a shelf item, attribute, attribute token, set of output streams, or set of groups for use within an action. The USING prefix precedes the action (or DO {action }* DONE) to which it applies.
OmniMark provides a set of features for specifying a particular SGML element, attribute, and data-attribute.
Often, an element can be referred to simply by its name. However, when the relationship between an element and another element is important, the element's name can be followed by an ancestry qualifier.
Ancestry qualifiers are used for examining an element's parent, grandparent, etc., and objects associated with them such as attributes and short reference maps. In the following list of ancestry qualifiers, gi refers to the name of an element in the document type definition (often referred to as a "generic identifier"). When ancestry-qualifier appears after an ancestry qualifier, the ancestry qualifier explicitly can be used to qualify another ancestry qualifier. For example,
NAME OF PARENT OF CURRENT ELEMENT an-alias
is the name of the parent of the currently opened element identified by "an-alias".
The descriptions define what is meant by the term after the OF keyword.
The most recently opened element that has the name gi
.
The currently open element referred to by the alias
defined
in the REPEAT OVER CURRENT ELEMENTS AS alias
action.
The outermost element of the instance.
This is useful for accessing the document element without knowing its name.
The most recently opened element.
The most recently opened element that has the name
gi
.
It can be either the element that was just opened or an ancestor of it.
The parent of the element.
An ancestor other than the parent.
Identify an element's attribute by its name.
Identify a data-attribute by its name.
Identify an element's attribute by its shelf index.
If the keyword SPECIFIED appears,
the shelf contains only the attributes specified in the element's start tag.
Identify a data-attribute by its shelf index.
If the keyword SPECIFIED appears,
the shelf contains only the data-attributes specified in the entity declaration instance.
Identify an attribute by an alias defined by a REPEAT OVER ATTRIBUTES or USING ATTRIBUTES.
Conditions take two forms. The form WHEN condition succeeds when condition is true. The form UNLESS condition succeeds when condition is false.
Conditions are grouped here according to the type of test.
numeric-expression
is defined in Numeric Values.
When UNANCHORED is included,
the match is successful if the pattern appears anywhere
in the text being scanned,
not just at the beginning.
Boolean values may be compared:
A boolean value is one of the following:
A boolean expression is any general test.
short-reference-map
is the name of a short reference map
as defined in the document type definition.
where attribute type
is one of SPECIFIED, DEFAULTED, IMPLIED, CDATA, ENTITY, ENTITIES, GROUP, ID, IDREF, IDREFS, NAME, NAMES, NMTOKEN, NMTOKENS, NOTATION, NUMBER, NUMBERS, NUTOKEN or NUTOKENS.
where attribute type
is one of SPECIFIED, DEFAULTED, IMPLIED, CDATA, GROUP, NAME, NAMES, NMTOKEN, NMTOKENS, NUMBER, NUMBERS, NUTOKEN or NUTOKENS.
where notation
is the name of the notation specified in the document
type definition.
Common forms are <, <=, =, >=, >, and != (inequality).
Multiple values may be compared, as long as all the values can be given the same type. All comparisons must be either non-ascending (no > or >=) or non-descending. != can only be used to compare exactly two values.
PROCESS
LOCAL COUNTER i INITIAL {3}
LOCAL STREAM s INITIAL {"b"}
LOCAL SWITCH w INITIAL {TRUE}
DO WHEN 1 < i <= "5" = 5 IS EQUAL 5 <= 99
OUTPUT "I knew that.%n"
DONE
DO WHEN 'a' < s < UL "C"
OUTPUT "I knew that too.%n"
DONE
DO WHEN true = TRUE = (! FALSE) = w = (3 + 4 = 2 + 5)
OUTPUT "Tell me something I don't know.%n"
DONE
HALT
Patterns consist of primary patterns, connected together with various operators, qualifiers, and occurrence indicators, as described in the following sub-sections:
Matches the text of string-expression
.
If UL is not specified, it matches the text exactly.
If it is specified, case is ignored.
Where character-set is:
static-string : any character in static-string .
character-class-name : any character in character-class-name .
character1 TO character2 : any character in the range from character1 to character2 (character1 and character2 must be single-character strings).
character-set1 OR character-set2 : any of the characters in character-set1 or character-set2 .
the character classes can be used by themselves or combined in character-sets :
| ANY | Matches any character. |
| ANY-TEXT | Matches any character except the character that represents the end of line. |
| SPACE | Matches a single space character. |
| BLANK | Matches either a single space character or a single tab character. |
| WHITE-SPACE | Matches a single space character, tab character, or end of line character. |
| DIGIT | Matches any of the characters "0" through "9". |
| LETTER | Matches any of the 26 upper-case or lower-case letters of the Roman alphabet. |
| LC | Matches any lower-case letter of the Roman alphabet. |
| UC | Matches any upper-case letter of the Roman alphabet. |
the position patterns match a point either side of a character:
| CONTENT-START | Recognizes the beginning of an elements content. |
| CONTENT-END | Recognizes the end of an elements content. |
| LINE-START | Recognizes the beginning of a line. |
| LINE-END | Recognizes the end of a line. |
| VALUE-START | Recognizes the beginning of a scanned value. |
| VALUE-END | Recognizes the end of a scanned value. |
| WORD-START | Recognizes the beginning of a string of letters and digits. |
| WORD-END | Recognizes the end of a string of letters and digits. |
Succeeds only if both the condition
is true and pattern
succeeds. If UL is specified, it applies only to pattern
.
Succeeds if condition
is true. UL has no effect here if specified.
In the following list P is a primary pattern. Note: In the following only, the braces represent themselves ("{" and "}") rather than the meta-syntax used elsewhere in this document.
P
may occur zero or one times.
P
may occur zero or many times.
P
must occur one time and may occur many times.
Succeeds if P
is matched exactly numeric-expression
times.
Succeeds if P
is matched at least numeric-expression1
times.
Input is consumed until either there are no more matches or
P
has been matched numeric-expression2
times.
Succeeds if P
is matched at least numeric-expression
times.
It continues to consume its input until there are no more matches.
The text matched by P
occurrence-indicator
is saved
in the pattern variable pattern-variable
,
and can be accessed by just referencing pattern-variable
.
The PATTERN keyword can be given before it.
The ANOTHER
keyword can be used inside a pattern, and is equivalent to the PATTERN
keyword.
The = is the supported V2 form of indicating pattern assignment.
By default, patterns in TRANSLATE rules match any kind of text from the SGML document. They can also be used to match the replacement text of internal entities or the names of internal entities or both. For example:
Match the expansion of the "&" SDATA entity.
Match any SDATA entity whose value is "[amp ]".
(The keyword VALUED is optional if only the value is being matched.)
NAMED and VALUED can be used together and the text following NAMED or VALUE replaced by any pattern-primary (so that the name or the value of an entity can be captured). These patterns can also be combined with others in the same TRANSLATE rule. The types of entities are:
Match an internal CDATA entity.
A CDATA entity contains text that is treated as character data when
referenced.
It is independent of specific systems, devices, or
application processes.
Match an SDATA entity.
An SDATA entity contains text which is treated as system data when referenced.
The text is dependent on a specific system, device, or application process.
Match either a CDATA or SDATA entity.
Text that is not part of a CDATA or SDATA entity can also be matched (the NAMED part is not allowed in these cases):
Match text that does not include replacement text
of a CDATA entity.
The matched text can include all or part of the
replacement text for one or more SDATA entities.
Match text that does not include replacement text for CDATA or SDATA entity.
PCDATA (parsed character data) is zero or more characters
that can be parsed without any markup being found.
Match text that does not include replacement text
of an SDATA entity.
The matched text can include all or part of the replacement
text for one or more CDATA entities.
Match any text include replacement text for a CDATA or SDATA entities. This is the default.
NAMED and/or VALUED can also be used in the pattern at the start of a PROCESSING-INSTRUCTION rule to capture a processing instruction that is the expansion of a PI entity.
Matches P1
then P2
.
Matches P1
only if it is immediately followed by text that matches P2
.
Text corresponding to P2
is not "consumed" as part of the match.
Matches P1 only if it is not immediately followed by text that matches P2 . A pattern can be inserted between LOOKAHEAD and NOT. The following matches P1 only if it is immediately followed by text that matches P2 and that text in turn is immediately followed by text that matches P3 :
P1 LOOKAHEAD P2 NOT P3
Matches either P1
or P2
.
The above list gives the precedence of combining patterns, from highest to lowest. For example, the pattern:
P1 P2 LOOKAHEAD P3 NOT P4 OR P5 LOOKAHEAD NOT P6 P7
has the following implicit parentheses:
((P1 P2) LOOKAHEAD P3 NOT P4) OR (P5 LOOKAHEAD NOT (P6 P7))
OmniMark has three different types of strings: static, dynamic, and those represented by an OmniMark expression. The term static-string refers to only static strings. However, the term string-expression refers to any type of string.
A static string can contain any character (except the newline or carriage-return character) and static format items.
Static format items are characters that can be evaluated without reference to the values of any shelves or variables. The following are static format items:
| %% | A percent sign |
| %_ | Alternative form for a space |
| %n | A newline sequence |
| %t | A tab character |
| %# | # |
| %b r{d1 ,d2 ,...dn } | Characters whose values are given by d1 ,d2 ,...dn in base b |
| %) | ) |
| %" | " |
| %' | ' |
| %@ | Interpolates arguments inside macro expansions |
| %@% | % inside macro expansions (used to dynamically construct format items) |
"%" can be replaced using the ESCAPE declaration.
Dynamic strings can contain any character or format item allowed in static strings, as well as the following dynamic format items. There are two kinds of dynamic format items: those used to emit the value of a shelf or variable (value-oriented format items), and those that affect the actual processing of output (processing-oriented format items).
The modifiers allowed for each format are in square brackets ("[" and "]"). One or more of these may be used, and in any order.
| %[fkjluw]a | Alpha representation of a counter |
| %[fnumber ]b | Binary representation of a counter |
| %[hlsuz]c | Contents of an element |
| %[fklrsuznumber ]d | Decimal representation of a counter |
| %[fklu]g | Contents of a stream buffer |
| %[fklu]i | Roman numeral representation of a counter |
| %[fklu]q | Name of the current element |
| %[fklu]q | Name of the current entity (in EXTERNAL-DATA-ENTITY and EXTERNAL-TEXT-ENTITY rules) |
| %[eop]q | Public and system identifier information associated with the current entity (in EXTERNAL-DATA-ENTITY and EXTERNAL-TEXT-ENTITY rules). The 'o' modifier cannot be used in EXTERNAL-TEXT-ENTITY rules. |
| %[fklu]v | Contents of an attribute (in general) |
| %[hlsuz]v | Contents of a CDATA element attribute |
| %[eop]v | Contents of an ENTITY or ENTITIES attribute |
| %[ep]v | Contents of a NOTATION attribute |
| %[fklu]x | Contents of a pattern variable |
| %y | Symbolic representation of a counter. |
| %sn | Strippable newline: emit a newline sequence only if one would not be emitted at the current point |
| %st | Strippable tab: emit a tab character only if no white-space character would be emitted at the current point |
| %s_ | Strippable space: emit a space only if no space or newline sequence would be emitted at the current point |
| %/ | Make the next character breakable |
| %[ | Stop counting characters towards the preferred width |
| %] | Restart counting characters again towards the preferred width |
| e | The system identifier associated with an attribute, entity, or notation, or the replacement text of an internal entity | ||||||||
| ep | The system identifier associated with the public identifier according to a LIBRARY declaration | ||||||||
| number f | Use a field width that contains at least number characters | ||||||||
| h | Suppress line-breaking | ||||||||
| j | Do not use "i", "l", or "o" in alphabetic lists (military style) | ||||||||
| k | Pad characters to the left of the value | ||||||||
| l | Convert alphabetic characters to their lower-case representations | ||||||||
| o | Access a notation associated with an attribute or external entity | ||||||||
| p | The public identifier associated with an attribute, entity, or notation | ||||||||
| number r | Print a number using base number | ||||||||
| s | For "%sc", strip extra white-space from the element's content | ||||||||
| s | For "%sd", remove trailing zeros after the decimal point, and the decimal point, if all digits following it are zeros | ||||||||
| u | Convert alphabetic characters to their upper-case representations | ||||||||
| w | For alphabetic lists, use "aa", "bb", "cc", etc., instead of "aa", "ab", "ac" | ||||||||
| z | For "%c" and "%v", suppress applying TRANSLATE rules to element's data content and to Cdata-attributes | ||||||||
| z | For "%d", pad the value with zeros on the left rather than with spaces | ||||||||
| number | For "%d", move the decimal point number places to the left | ||||||||
| number | For "%b", use the ordering given by number
.
number
should be one of:
|
Returns the value of an attribute.
Returns the value of an attribute on the ATTRIBUTES shelf.
Returns the value of a data-attribute.
Returns the value of a data-attribute on the DATA-ATTRIBUTES shelf.
Uses special date format items to return the string value of date
and time information.
Similar to DATE, but calculates the info at compile-time. Useful
for labelling .csc files.
Returns the external name that function-name
is defined as.
Returns the name of the library where function-name
can be found.
Returns the real name of the
attribute associated with the alias
name.
Returns the name of an opened element's attribute (i.e. its "key" on the ATTRIBUTES shelf).
The real name of the attribute associated with the alias
name.
Returns the name of a data-attribute (i.e. its "key" on the DATA-ATTRIBUTES shelf).
Returns the key of a referent shelf.
Returns the key of a stream, counter, or switch shelf.
Returns the key of the selected referent.
It can be used only within a USING REFERENTS or REPEAT OVER REFERENTS body.
Returns the name of the element defined by the ancestry qualifier.
Returns the name of the file or referent associated with the given stream.
Returns the text of a stream that was opened as a buffer or
referent and then later closed.
Returns the text of the indicated pattern variable.
Output a value to be determined at some other point of processing.
Like REFERENT, but the named referent doesn't go on the REFERENTS shelf.
Call to a string function.
string1 JOIN string2 string1 || string2
This just connects the two strings together.
string REPEATED number string ||* number
This produces string
repeated number
times.
A numeric-value can take the following forms:
Converts a string of characters to a number as if the string were the
binary representation of that number.
As the one-argument form of BINARY except that the numeric-value
specifies the order in which the bytes in the string are to be converted.
Convert the number represented by string expression
to a number using numeric-value
as the base. Letters are used to represent digits above 9 for bases 11 up to 36 inclusive. A leading sign is allowed.
Returns the number of subelements of an element.
Returns the current value of the counter
Returns the position on the attributes' shelf of the attribute
with key string-expression
.
Returns the position on the data-attributes' shelf of the data-attribute
with key string-expression
.
Returns the position of the item on the shelf with the given key.
Returns the length of the indicated string.
Returns the number of attributes associated with an element.
If SPECIFIED appears,
only attributes specified in the document instance are counted.
Returns the number of currently open elements.
Returns the number of currently open subdocuments invoked by the DO
SGML-PARSE SUBDOCUMENT ... compound action.
Returns the number of data-attributes associated with an attribute.
If SPECIFIED appears,
only data-attributes specified in the document instance are counted.
Returns the number of shelves that currently exist.
Returns the number of referents that currently exist.
Returns the number of consecutive occurrences of a currently
open element.
Calls another program while OmniMark is running.
The parameter string-expression
is the command to execute, which typically consists of a program name followed by the program's arguments.
The value returned is the value the called program returns to the
operating system.
V2 holdover for coercing comparisons to numeric expressions. No
longer necessary.
A base-10 number.
Any string-expression
found where a numeric-value
is expected is interpreted as a base-10 number, with a leading sign allowed.
Call to a numeric function.
The following operators are allowed, in the order of highest precedence to lowest:
+, -, bit-wise COMPLEMENT
*, / and MODULO, bit-wise MASK and SHIFT
+ and -, bit-wise UNION and DIFFERENCE
This section defines many of the terms mentioned but not defined in the previous sections.
Local declarations are in effect for a single scope. Any local declaration can be used at the start of any scope.
The shelf can be used in any of the actions that follow it in the scope.
The shelf's value is saved at the start of the scope and restored at the end of the scope. The shelf can be used by any rule that is active inside of the current one.
Like SAVE, except that the shelf is, in addition, CLEARed at the start of the scope.
Save away all the active groups at the start of the scope, and restore them at the scope's end.
Shelves are the OmniMark equivalent of an array. They can be of type COUNTER, STREAM, or SWITCH. A shelf declaration has the following forms:
size has the form
INITIAL-SIZE constant numeric expression.
init-values has the form
INITIAL '{' init-value {, init-value}* '}'
init-value has the form
value {WITH KEY constant string expression}?
value must be constant and of the appropriate type.
Items on a shelf (array) are accessed using an index . OmniMark provides two indexes:
by position.
by key value.
use the last item of the shelf, even if in a USING block, REPEAT
OVER block, or function.
When a new item on a shelf is created, it can be explicitly placed either before a point in the shelf or after:
1 <= n
<= shelf-size
+ 1
0 <= n
<= shelf-size
The shelf must have KEY str
.
Same as putting the shelf BEFORE the item with the given key.
If no insertion point is specified, the new item is placed on the end of the shelf.
OmniMark provides a single data structure, called a stream, for referring to different files, saving portions of a document for later reference, data movement forward or backward in a file, and manipulating strings of text.
Provides access to the APPINFO parameter in the SGML Declaration.
Refers to the active streams in the domain in which it is
referenced (#OUTPUT in V2).
Provides the name of the document element.
Refers to the standard error output.
A shelf of streams.
Each stream contains a string corresponding to
the value of one of the libpath
parameters entered on the command line.
A shelf of streams.
Each stream contains a string corresponding to a string specified in
a LIBRARY declaration (See Other Declarations).
A shelf of streams used for matching public identifiers.
The key of each stream is the public identifier and the value of the
stream is the value of that public identifier.
The contents of the filenames specified on the command-line.
Refers to standard output.
The #MAIN-OUTPUT stream is the target of the -of control argument
given on the command line. (OUTPUT in V2).
Refers to the standard input. This can only be read.
Refers to the standard output independently of where the
OUTPUT stream is bound (#CONSOLE in V2).
Refers to the stream attached to the input of the SGML parser (SGML in V2).
Anything written to the #SUPPRESS stream is discarded.
The following modifiers may be used when opening streams
Specifies the ordering for all %b format items written to the named stream.
Defines acceptable line widths.
Indicates the named stream may be manipulated by the FIND and
the ELEMENT domains, and if there is one, the SGML-ERROR domain.
Referents may be written to the indicated destination.
Referents may be written to the indicated destination, but
only their names will be written to it, not their eventual value.
Referents may not be written to the indicated destination.
Any combination of these element content modifiers (except "u" and
"l" together) may be used to specify how element content should be
processed when written to the specified stream.
All of the above modifiers are allowed for OPEN and REOPEN actions. Only the BINARY and element content modifiers are allowed for PUT actions.
Write string-content
to the active streams.
Change active streams to stream
.
Write string-content
to stream
, temporarily making it the active stream.
The initial active stream ("standard output" or the destination
specified with the -of command-line option).
).
The currently active streams.
Position in a REPEAT OVER loop.
Number of errors encountered in current sgml-parse.
Number of warnings encountered in current sgml-parse.
Number of errors encountered in processing so far.
Number of warnings encountered in processing so far.
All date format items for the DATE string expression start with an equal sign ("="). A lower-case "x" can be used or not with the formats indicated. When used, it signifies that that number should be formatted as two digits, with a leading zero added, if required, or in the case of "=xY", with the century part removed. When "x" is not used, then exactly as many digits are required are used (four for "=Y", and one or two otherwise). The valid format items are:
| =xH | Hour in 24-hour form |
| =xh | Hour in 12-hour form |
| =xm | Minute |
| =xs | Seconds (no fraction) |
| =xS | Seconds (with a fraction if available on the host system) |
| =a | The letter "a" for the first 12 hours of the day, "p" otherwise. |
| =A | Like a, only this produces "A" or "P". |
| =xY | The year |
| =xM | The number of the month (1 for January, etc.) |
| =n | The English name of the month (e.g. January) |
| =xD | The number of the day in the month |
| =W | The English name of the day of the week (e.g. Tuesday) |
| == | A single "=" character |
DEFINE {COUNTER | STREAM | SWITCH}? FUNCTION function name
prototype ELSEWHERE
DEFINE {COUNTER | STREAM | SWITCH}? FUNCTION function name
prototype AS
local*
action*
DEFINE EXTERNAL
{COUNTER | STREAM | SWITCH | SOURCE | OUTPUT}?
FUNCTION function name prototype AS constant string expression
{IN FUNCTION-LIBRARY constant string expression}?
The first string gives the name of the external function as it is defined in the external source file. The second string gives the library to look up the function in. If 'DECLARE FUNCTION-LIBRARY' has been given, the function-library need not be specified.
When the prototype is parenthesized in the definition, the call's arguments must also be parenthesized. Forms are:
No arguments for parenthesized prototypes only.
In unparenthesized functions, psep is a name. In parenthesized functions, it may be a name or a comma. arg has the form:
arg-type shelf-type shelf-name opt-init
arg-type is one of
Argument is a shelf that can be changed in any way.
Argument is a shelf that can be read, but not modified.
Argument is a single-item shelf that can only be read.
Argument is a multi-item shelf that can only be read,
and is composed of multiple elements when the function is called. Not
supported in external functions.
opt-init has the form:
OPTIONAL INITIAL {value}
The OPTIONAL keyword may only be used in internal functions, and cannot be applied to REMAINDER arguments.
INITIAL values may only be specified for OPTIONAL VALUE arguments.
The name of the function, followed by a correct argument list, is sufficient to identify the function. There is no keyword that says "This is a function call."
OmniMark provides a general-purpose macro capability that allows a user-defined name to abbreviate a more complicated expression. Macros are a programming convenience. They can be assigned to delimited characters so that a special character substitutes for a longer expression. Macros can also be parameterized so that a repeating but variable pattern can also be shortened.
The syntax for declaring a macro is as follows:
MACRO macro-name {token}+
arguments
IS
replacement
MACRO-END
where
is one or more OmniMark names or delimiters which must follow the
argument when the macro is used.
Possible delimiters include any of these characters:
( ) { } [ ] ! @ $ % ^ & * - + = | \ ~ ` : < , > . ? /
is a name that is replaced by text specified when the macro is invoked.
is the text inserted when the macro is called.
The syntax for calling a macro is as follows:
macro-name arguments